You arrive in a new city for the first time, and you’ll need to consider taking a taxi as one of your options for getting around. Given your prior experience in other cities, you estimate initally that the expected cost of a ride is related to the distance of a ride as follows:
You arrive in a new city for the first time, and you’ll need to consider taking a taxi as one of your options for getting around. Given your prior experience in other cities, you estimate initally that the expected cost of a ride is related to the distance of a ride as follows:
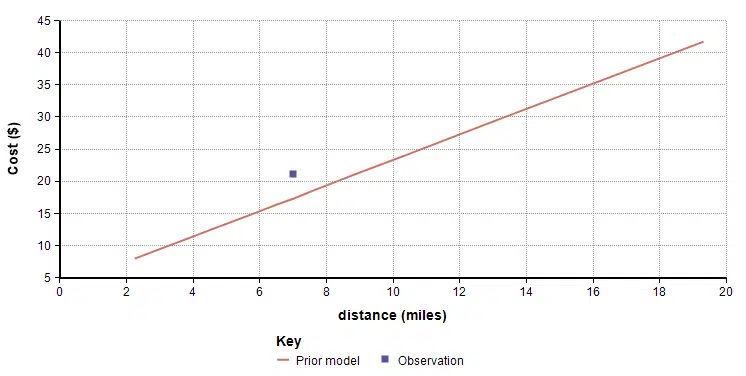
cost ≈ $2/mile * distance + $3
For any given ride, there will be a random fluctuation from the expected cost, so this is really just a model of the mean cost.
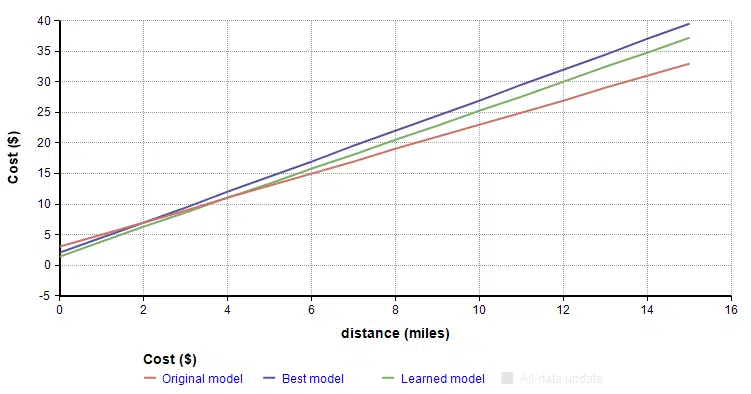
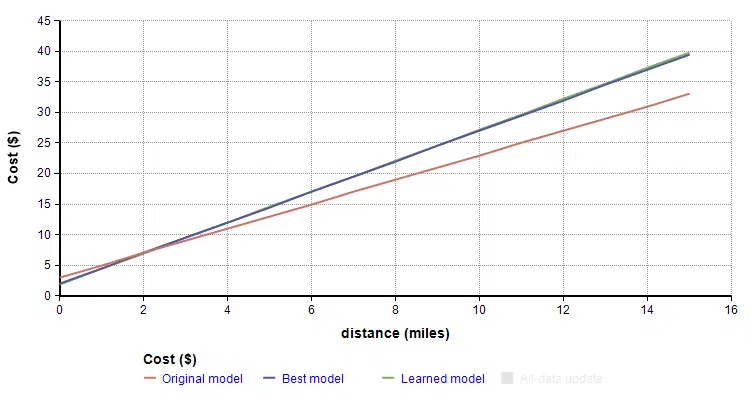
You had to come up with the parameters of this linear model — the $2/mile and the $3 fixed cost — based or your prior experience in other cities. Even though you are pretty experienced with these things, you’ll want to adjust parameters for this city as you get experience taking taxis here.
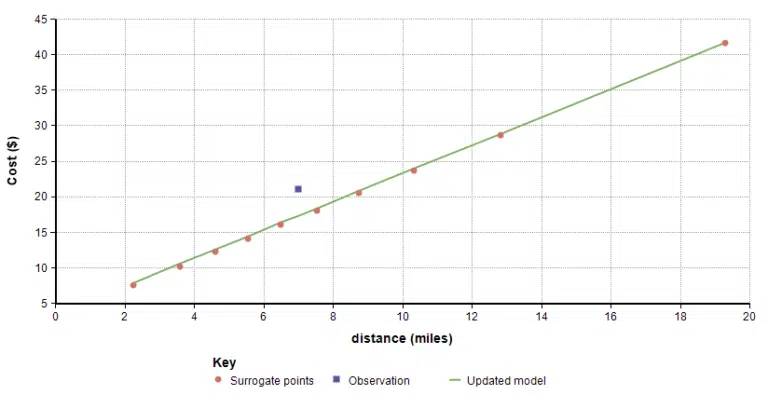
So now, you take your first ride in the new city, a 7 mile trip for $21. Your initial model predicts a cost of $17, so it seems like you should increase the two parameters of your model a bit. But by how much?